I'm still playing through the Assassin's Creed franchise. But now I've finished Rogue and have moved on to Unity which--although released on the same day--are (console) generations apart. However, this also means that the games were created with different Ubisoft game engines: AC:Rogue was the last game on AnvilNext and AC:Unity was the first game on AnvilNext 2.0.
Different engines ostensibly have different issues, and older engines can have issues on newer hardware. My previous post describes my issues with AC:Rogue where the game would stall for seconds at a time with too many CPUs. And I run an AMD Threadripper 5975W with 32 cores/64 hyperthreads--difficult hardware to come by 10-12 years ago when these engines were created.
Turns out that AC:Unity also has problems with too many CPUs--it crashes to desktop immediately after launch!
Has this already been fixed?
The first step was to see if anyone else has run into this problem and if they've fixed it. Turns out I was in luck. A reddit user running on the same CPU had the same issue. Unfortunately, the workaround was pretty sucky--disable CPU cores in the BIOS. I definitely don't want to have to reboot before and after playing the game.
Fortunately now we know what the problem is--too many CPUs. The fix in the previous blog post was similar, but since this is the second game I've had to fix in the same way, let's see if we can make a fix that is more generic.
Let's make a generic tool! But how?
Enter Microsoft Detours--an amazing tool for hacking (and even some legitimate uses). Basically the plan is to create a .DLL file that we can inject into the process that will intercept (or hook) some system calls and lie present an alternative set of facts to the game. This .DLL can be used with nearly any game, so we could go back and use it with Rogue to fix it without hacking the assembly language.
In the previous post, we pointed out two system calls (GetSystemInfo and GetNativeSystemInfo) that tell us the number of CPUs, but this is just the tip of the iceberg. It turns out that AC:Unity uses many more system calls than this. And for our generic tool to support all games, we should at least figure out what AC:Unity is using and support those calls.
But where do we draw the line? In the past 20+ years we have gone from single CPU to multiple SMP CPUs, to NUMA. Machines are available these days that have over 64 CPUs. AMD is preparing to launch servers with 256 cores next year (order now!). Now it's unlikely people will run games on these machines, but that was probably the thinking back when 32+ CPU machines were unheard-of. The point is that modern Operating Systems have evolved and added system calls to support NUMA, CPU Groups and CPU Sets. While it's conceivable that games could call some or all of these, let's assume that they won't. But maybe we can set up some logging for these functions to see if they're ever called.
The bigger issue is probably going to be affinity. Simply put, affinity is a list of CPUs that a process (or threads) can run on. Typically this list is given as a bit mask since each bit can effectively represent a CPU. Since (historically) the number of CPUs was small, this was fine for a 32-bit value, but now we have over 32 CPUs! No longer can a single 32-bit value represent an affinity mask. Older 32-bit applications typically used a 32-bit value, but newer 64-bit applications generally use 64 bits (but bugs may exist from porting previous code, etc.).
Intercepting Functions
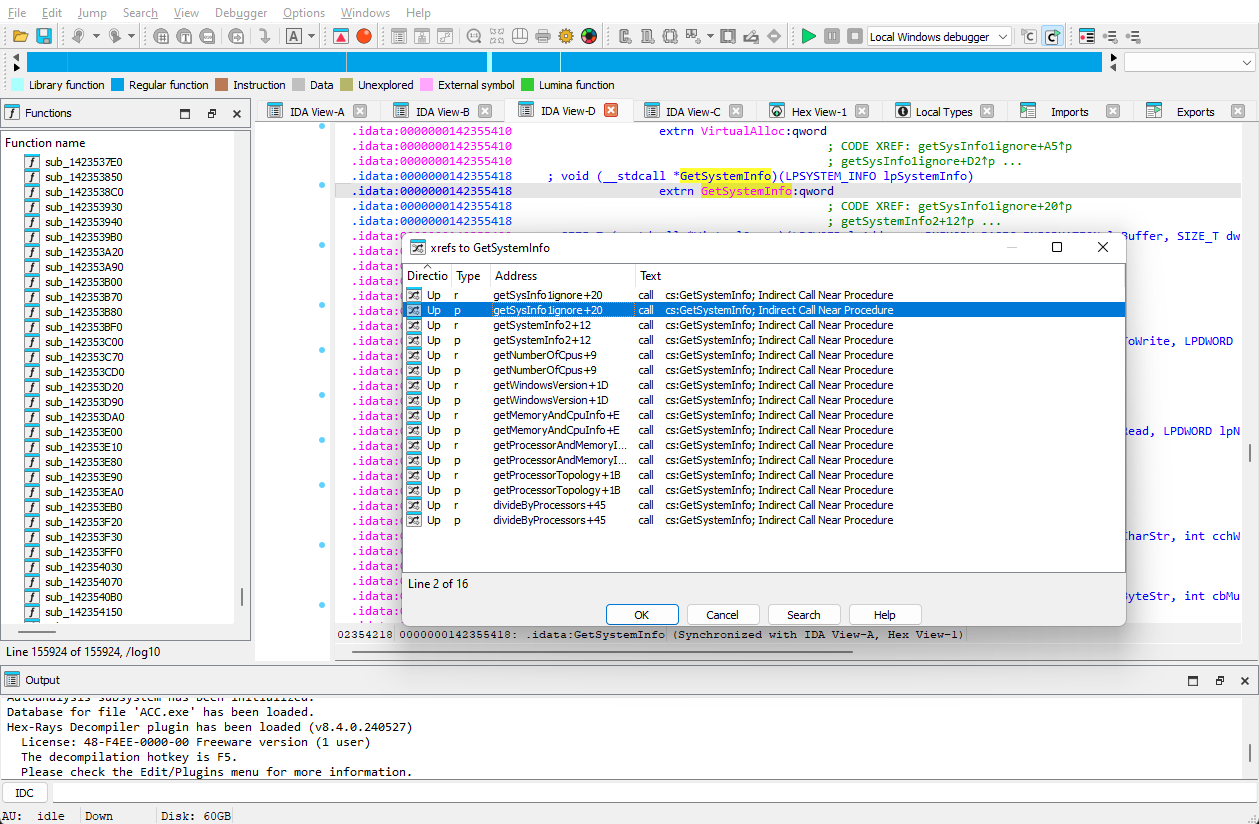
The Detours wiki has a pretty simple minimum example for hooking instrumenting the Sleep function. Let's alter it for GetSystemInfo, one of the functions that we'll need to intercept. (Source Listing)
This listing will compile into a .DLL that, when loaded by an application, will override calls to GetSystemInfo and allow us to alter the responses.
Once DetourTransactionCommit() is called in our InstallDetours() function our hook is in place:

Now whenever GetSystemInfo is called, our version is called instead. We just happen to call the original and then modify the number of processors:

The next step is that we need to get the game to load our new DLL. Unfortunately, this is easier said than done. Games these days typically don't want hackers messing with them and they go to great lengths to try to prevent that (just as I did when working on my games). AC:Rogue didn't have any protections, but AC:Unity has a multiplayer element to it, and multiplayer games typically make attempts to curb hacking/cheating. Now I'm just trying to get the game to run but it doesn't know that.
Detours has (at least) two tools that can be used. The WithDll tool can be used to launch an application and inject a DLL before it fully loads. Unfortunately this method didn't work with AC:Unity because of how it's launched. I purchased the game through Steam, so Steam launches AC:Unity, which sees that it wasn't launched from Ubisoft Connect, so it launches Ubisoft Connect and exits, which does a few things (cloud sync for instance) and then re-launches AC:Unity. Since I cannot control how the game is launched from Ubisoft Connect, this didn't pan out. Interestingly though the app did launch with the injected DLL.
The other tool is SetDll. This tool can modify an executable file to always load a new DLL. This sounds like exactly what we need! Unfortunately, this didn't work either since AC:Unity has hack-prevention checks that noticed that the executable was modified and refused to run.
Frustrated, I started looking in to other ways to inject the DLL. SetDll works on DLLs too, so if I can catch it early enough in the loading process, I could use a different DLL as an injection vector. I fired up Process Monitor and fiddled with the filters to see what the AC:Unity process was doing when it started. Turns out it ships with a DLL that is loaded very early, and that DLL doesn't complain about modifications. Eureka! I have my injection vector.
I added some simple logging (using OutputDebugString that I could view with the DebugView utility) to my simple example to make sure that my function was being called (since AC:Unity also detects debuggers and terminates the process if one is found). Good news--it was being called! But of course, the game was still crashing. So while this was enough to essentially fix AC:Rogue, the newer engine does different things and will need more work.
Affinity Functions
As I mentioned above, the functions that control affinity are probably in use. The Microsoft article about Processor Groups has a good list of functions that control affinity and scheduling. My process was to first add logging for these functions to see if they were being called. The logging would include what arguments that AC:Unity was passing to the functions as well as what the functions returned. Turns out that several of them were being called. Even though GetSystemInfo (and GetNativeSystemInfo) were intercepted and showing a lower number of CPUs, the affinity functions were happily reporting affinity across a larger number of CPUs.
The next process was to change the behavior of these affinity functions to only return bits set for the number of processors that we were emulating.
An interesting function that it turns out AC:Unity was also calling is SetThreadIdealProcessor (and the extended version). This function gives the Windows scheduler a hint about which CPU to schedule the thread on, but it's not as strong as affinity. I also intercepted this function to only allow the processors in our emulated set.
Logical Processor Info
In my work hacking AC:Rogue I discovered that it was optionally looking for and calling a function called GetLogicalProcessorInformation (which also has an extended version). CPUs these days are very complicated: they have multiple layers of caching (some of which are shared with other cores), can share hyperthreads with other cores, not to mention the NUMA relationships. These functions are the means to access this data on Windows, and as you might expect, are quite complicated. The extended version is even more complicated allowing different means of querying data and returning variable-sized information.
It turns out that AC:Unity was also calling these functions, so they are another one that I had to wrangle.
For the original function, all of the data is presented at the same time, so the function returns the same data every time it is called (at least, it is highly unlikely that it would change while the game is running). Therefore, it is easily cached. The first time my intercepted function is called, it queries all of the host data, chops it down to only include our emulated processors, and saves it off so that every subsequent time that we're called we just return the same data.
Unfortunately, the extended function allows specifying a Relationship Type to query, and the data is drastically different based on that query type. My solution here was to cache the chopped-down host data and remember the Relationship Type along with it. So if a different Relationship Type was queried I would throw away the cache and rebuild it. This however was much more complicated because of the variable-sized data. I essentially had to filter the data in place and then copy the filtered data into the cache. For this it's probably better to look at the code directly: (intercept function, cache builder)
Does it run now?
YES! 🎉
In the end, I ended up hooking 12 functions (but three--the Process Group functions--weren't called by AC:Unity and therefore only log).

Finally, I can play the game for a bit.
But... oh no. There's another problem.
The Video Problem
I have a Samsung Odyssey G9 49" monitor. It's aspect ratio is 32:9 and I'm playing a game originally designed to run on consoles that output 16:9. However, the PC port of the game itself beautifully figures out the correct aspect and does pretty well with the super ultrawide display, as evidenced in the screenshot at the top of this post.
The problem is the full-motion videos that it uses for cutscenes. They are originally designed for 16:9 and are stretched out to 32:9--double the width they should be. It's almost breaking my brain trying to watch them and figure out what's going on.
|
| A very wide Mr. Templar tied to a tree |

Can I fix this too?
Bink Video
Bink is a popular video encoder and player software package for games. Developed by RAD Game Tools (now owned by Epic and rechristened as Epic Game Tools), Bink was originally released way back in 1999.
Bink is pretty easy to integrate and very fast. I integrated it in to EverQuest 2 back in 2006, so I'm somewhat familiar with the API.
Turns out that Ubisoft uses it in AC:Unity, though a much newer version than the one I used. Fortunately a lot of the API seems to have remained consistent. And all I want to do is prevent the videos from being stretched.
Research
The first step is to figure out how AC:Unity is using Bink. Fortunately I already have the means to do this, just like I did with the CPU Windows system functions--hook the API calls and see how they're being called. Bink is loaded as a DLL, so theoretically I can hook it too.
And the initial tests are promising. I used Microsoft's dumpbin tool to list the exports from the Bink DLL. Pretty much any application is guaranteed to call BinkOpen, so that's the first function that I hook. And testing is quite quick since the first thing AC:Unity shows is the Ubisoft logo video.
Unfortunately, this is where things hit a snag. I've managed to hook a few functions that give me useful information (I can see BinkRegisterFrameBuffers called for instance), but none of the functions with names that sound promising are ever called (BinkCopyToBuffer, BinkCopyToBufferRect, BinkBufferOpen, BinkBufferSetResolution, BinkBufferSetScale). I ended up hooking 20+ of the most interesting sounding functions only to see a tiny few of them being called. How is it accessing the data without calling BinkCopyToBuffer?!?
It's time to get dirty. I can't attach a debugger because of the anti-hack measures (and it will take way too long to reverse engineer those), but I need to see it in a debugger when it's trying to access the data. So I'll make the game hang when it tries to access the framebuffer!
It turns out this isn't too complicated: I register an unhandled exception filter that just sleeps infinitely when a crash happens, and then I call VirtualProtect to tell Windows to make the framebuffer data no-access--any attempt to read or write to it will cause a crash. However, I have to allow Bink to write the data in to the framebuffer, I just want to see where it's read back out, so I have to allow access to the BinkDoFrame function.
As soon as the game hangs (without displaying the first video frame) I use Task Manager to write a full dump. But the dump is confusing. I have no symbols, no function names, nothing to really give me any clues as to what's happening except the assembly code. And it looks like AC:Unity is reading the data directly out of the framebuffers.
That's exactly what it's doing. AC:Unity is calling BinkRegisterFrameBuffers which means it is allocating its own framebuffers and undoubtedly retaining the pointers. BinkDoFrame will decompress the video stream into the framebuffer, and then AC:Unity is reading the data (probably with a shader) to display on the screen.
The video fix
Looking at the allocated framebuffers, they're 1920 x 1080 (16:9 ratio) and their shaders are probably the stretching culprit. I'm not a GPU/graphics guy (ironic given where I work) and I have no idea how to break into the game's shader pipeline. It can be done because there are other mods out there that do, but it will take a long time to learn how to do this. And I want to get back to playing the game, so how do I do it quickly? Is there something I can do to the framebuffers?
It turns out I can! I need AC:Unity to allocate 32:9 framebuffers instead of 16:9, and the first two values in the structure returned from BinkOpen looks like width and height. So the first thing I try is just scaling that width to 32:9. Since buffers historically were powers of two, they typically have a pitch passed to the decoder that says how many bytes represent a line so that it can skip to the start of the next line (extra bytes would just be off the screen). This helps us out here since the pitch tells Bink to skip about half of the line and just start decoding on the next line. It works!
 |
| Better? |
Well, kinda. Why is half of the screen green? Hey, but at least the aspect ratio is correct. And it's not centered, but we can fix that too (probably).
Alright, so the green screen. Encoding video data as RGB is very inefficient. Remember, Bink is a library developed in 1999 and first used on the PlayStation. It uses the YCrCb color space for its video information to use less space. AC:Unity likely has a pixel shader that computes the RGB values from the YCrCb planes that the framebuffers are allocated from. The buffers started with zeroed bytes and since the right half of the screen is never written to by the decoder, they remain as zeroed bytes. Well converting the zero values for YCrCb ends up with RGB color #008700, a quite greenish hue.
Looking up the value for black in YCrCb and setting the initial state of the buffers to those values gives us a dark gray. Not quite black. But that link has the minimum Y value as 16, which gives us a dark gray, but trying a Y value of 0 gives us black.
So the last issue to tackle is the centering. AC:Unity has given Bink the addresses for the framebuffers by calling BinkRegisterFrameBuffers. Bink decodes data into the first line at the start of the buffer, advances the line pointer by pitch bytes and decodes the next line, so on and so forth. If we can tell it to use a different starting address for the buffer that represents a centered frame, it will move the whole image.
This is pretty easily done, we can just calculate the scaled width of our screen, subtract the width of the video and divide by two to get the framebuffer line offset. We have to do this for each plane separately because the Cr and Cb planes are smaller than the Y/A planes. The tricky thing here though is that Bink requires the framebuffer address to be 16-byte aligned, otherwise a hang occurs in the decoder (speaking from experience).
Voila!
 |
| Not so wide now, Mr. Templar! |
Source is here. Uploaded to NexusMods and now back to playing the game!