I recently uploaded to github a
C++ template library called Thor, which is something that I've been playing around with. It's really just a way for me to write some crazy template code--a creative outlet if you will. This blog post is meant to show off some of the things that I'm proud of in Thor. The name Thor came in part because of inspiration from
Andrei Alexandrescu's template library
Loki and his book
Modern C++ Design (an excellent advanced C++ book).
Some things in my Thor library are just me implementing things in the way I would if I had full control, and some are a slightly different take on popular concepts. Some things are already outmoded based on offerings in C++11 (especially in terms of atomic support), but are included for posterity.
I apologize that the code samples are images (Blogger currently doesn't do well with template syntax), but generally a link is provided to the code on github.
Containers
The C++ standard library includes several standard, well-known and well-documented containers, however these containers don't often allow for much customization. For instance, std::vector (up until the C++11 standard) had no obvious means to free memory (C++11 adds the shrink_to_fit() function). Although
not technically correct, I'll refer to the C++ standard library as STL below for brevity's sake.
thor::basic_string
Thor's string class works very similarly to
std::string and
std::wstring with a few changes. First, the strings are atomically reference counted, so the underlying string data is shared when possible. Secondly, a template parameter can be specified to pre-reserve (as part of the basic_string instance, not a separate heap allocation) space for the string. The default of zero is a fully dynamic string, but if you need a quick string on the stack and don't want to allocate anything from the heap, it is easily done with the addition of a size template paramter:
Furthermore, in addition the STL constructors for basic_string, additional options are available for printf-style formatting and literal strings (that don't require copying or allocation):
The printf-style formatting is also supported for append, insert, replace and assign variants.
Thor's string also supports conversion between
UTF-8 and "wide" (
wchar_t). If
wchar_t is 32-bits, then the conversion will be between UTF-8 and
UTF-32, however the more likely case is that
wchar_t is 16-bits, in which case the conversion will be between UTF-8 and UTF-16, complete with support for
UTF-16 surrogate pairs.
thor::list
In general node-based STL containers (such as std::list) will allocate a 'dead node' or a terminator node from the heap as soon as they're constructed (even default constructed). Usually this terminator node will include space for the 'T' stored type, although that space will never be used and therefore wastes space. I frown upon the fact that wasted space is allocated from the slower heap for such a simple operation as default constructing a list.
Consider
Thor's list class. Instead of heap-allocating a terminator node, the head/tail pointers for the list class use a list_node_base and the
address of the list_node_base is used as the terminator. Thus, the terminator (used by the end() iterator) is implemented as such:
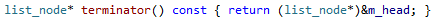
This has the advantage of not requiring a heap allocation for the terminator node while still allowing for simple reverse iteration and no need for null-pointer checking at head/tail. However, there are two disadvantages. The first is that any accidental writes to the end() iterator (which is completely invalid anyways) may cause memory corruption. This can be prevented in checked/debug builds with asserts when trying to dereference the end() iterator. The second is that swap semantics require slightly more finesse (although these are more complicated in Thor for another reason explained below). In std::list the swap() function must only exchange pointers and counts between two lists--since the terminator node is allocated on the heap it is not tied to either list and is automatically part of the swap. However, since Thor's list essentially has a local terminator node as part of the instance, care must be taken to fix up the terminators during swap:

Notice that the swap function handles a concept of shareable. This is because of another enhancement of Thor's containers. Essentially, space for a certain number of items can be pre-allocated along with the container, similarly to the string class mentioned above. For instance,
thor::list<T,5> specifies that no heap allocations must occur for the first five list entries. Fortunately, thor::list<T,5> inherits from thor::list<T> so that it can be used anywhere where a list is required. However, it also means that the problem of swap() now must handle pre-allocated nodes. It is less efficient to swap() a list with pre-allocated nodes as this requires the nodes be converted to heap allocated nodes.
There are many other extensions to all of the containers, yet they all try to remain true to the C++ standard library specification.
thor::hash_map (et al)
The
thor::hashtable class (which forms the basis of hash_map, hash_set and the multi- versions of each) has a noteworthy feature: a
policy class that controls how the stored values are organized into buckets. The options are a power-of-two system that is very fast by using bitwise masks instead of divide/mod instructions (although this method can be terrible for pointers as keys as they typically are multiples of 4 or 8 and the bucket strategy loses efficiency leading to collisions), or a more traditional (and slower yet less collision-prone) prime-number strategy.
The C++ standard library hash containers are undefined order containers. This means that the order in which you insert items is not necessarily the same order in which you would iterate over the items. However, thor's hash containers are a fusion of a list and a hashtable, which allows for a defined iteration order as well as amortized O(1) lookup time. This does require a slight change to how iteration starts: the
begin() function defaults to 'list' iteration mode but can be changed to 'hash' iteration mode, whereas
find() operations default to 'hash' iteration mode.
Embedded Containers
For
std::list (or
thor::list for that matter), the '
T' type that you're storing in the container is contained within a node that tracks other information for the container. If you had a list of pointers to objects in the heap, then the objects were allocated and the list container must allocate a small node to store the pointer. This is wasteful. The embedded containers can alleviate this by having the node tracking information as part of the object that is being stored. For instance, the '
T' type stored in a
thor::embedded_list must contain an
embedded_list_link member and the member is given as a template parameter to
thor::embedded_list.
Atomic integer/pointer
The
thor::atomic_integer system is similar to C++11's
atomic wrapper, so while not completely necessary it was a fun exercise to write. The real meat of how it works is based in the platform-specific interlocked system (the Windows version is
interlocked_win). This uses template specialization to handle one-, two-, four- and eight-byte integers. By using intrinsics, these atomic_integers actually compile down to very few inline instructions for most operations. Consider how declaring interlocked
works on a platform with a 32-bit integer. First, some magic happens based on how the non-specialized interlocked class is declared. There is a second template parameter that is required, but defaults to sizeof(T):
The template parameter
T_SIZE defaults to 4 for
int, which causes a specialization to be selected:
This specialization uses the correct functions/intrinsics for the numeric type that we're wrapping in atomic_integer. This allows
atomic_integer to do the correct operation based on size of the integer parameter:
Memory Alignment
Another place where Thor uses template specialization is with memory alignment. All of the containers do memory allocation through Thor's
memory functions. There is a simple class called the align_selector:
This class's only job is to determine if an object can use system-guaranteed alignment or not (most objects can). If the system alignment will suffice, alignment_selector::alignment will be zero. The align_alloc class uses the align_selector as a default template parameter to select the proper specialization for the alignment:
The system default alignment just allocates raw bytes:
But the default version that handles non-default alignments will over-allocate and offset:
Arguably, this version could use
_aligned_malloc or memalign or similar, but by using new[] an application may still override new and use their own memory manager if so desired.
There is a lot more to the Thor library. Take a look at it on github and let me know what you think.